Reconstructing Animals and the Wild
Peter Kulits, Michael J. Black, Silvia Zuffi
CVPR 2025
![]()
![]()
![]()
![]()
Summary
We train an LLM to decode a frozen CLIP embedding of a natural image into a structured compositional scene representation encompassing both animals and their habitats.






Goal
To reconstruct 3D animals, scene objects, and layout from a single image of a natural environment.
Problem
In contrast with the geometric regularity of the man-made world, natural environments are considerably more diverse and varied, resulting in the breakdown of discrete concepts or labels.
Solution
Rather than teaching the model to reconstruct the scene in terms of discrete categorical classes, we train it to estimate continuous semantic appearance, enabling generalization.
Dataset
Teaching a model to decompose single images of animals and their natural environments into structured 3D representations requires broad compositional understanding, yet acquiring suitable training data presents its own challenges. Because the 3D scanning of nature at scale is impractical, here we exploit synthetic data. Building upon tools introduced by the Infinigen project, we design a data generator to construct RAW, a million-image dataset comprising both synthetic animals and their environments:


















Model
Our goal is to approximately reconstruct 3D animals, scene objects, and layout from a single natural image. To that end, we design a structured graphics-program representation, or language:
set_sun_intensity(0.981)
set_sun_elevation(0.691)
set_sun_size(0.811)
set_camera(88.130)
set_atmospheric_density(0.009)
set_ozone(1.499)
set_sun_rotation(231.110)
set_dust(0.169)
set_sun_strength(0.212)
set_air(0.771)
set_ground([CLIP])
add(pixels=1582, loc=(-0.553, -0.809, -22.591), height=1.365, rotation=[ROT], appearance=[CLIP])
add(pixels=111, loc=(-1.524, -0.939, -30.159), height=1.224, rotation=[ROT], appearance=[CLIP])
...
Akin to IG-LLM, we train an LLM to decode CLIP image features into graphics code where objects are represented by their asset names. However, when naively training the language model to produce this sequence, we observe that the model fails to scale to the broad asset collection -- while capturing the layout, it confuses objects with another (e.g., a tiger with a bush, a bird with a boulder):




We hypothesize this inconsistency arises due to limitations in train-time supervision. Built upon a causal LLM, the model operates autoregressively, reconstructing scenes in incremental chunks of text known as tokens. During training, language models are typically optimized through a cross-entropy next-token objective, whereby they learn to predict the probabilities of the subsequent token conditioned on the preceding ones. Although this discrete text-based representation and supervision excel in capturing distinct categorical attributes such as "small," "purple," "shiny," or "cube," the supervision is binary, where names lack a meaningful distance metric between one another. We suggest that, rather than teaching the LLM to infer exact individual assets by name, of which many have only fine-grained differences, the model can be taught to estimate continuous semantic appearance, where assets are represented by their CLIP encodings. We do so by adding a unique token, [CLIP], which signals the LLM hidden state should bypass the discretizing tokenization process and, instead, be passed through a linear projection:
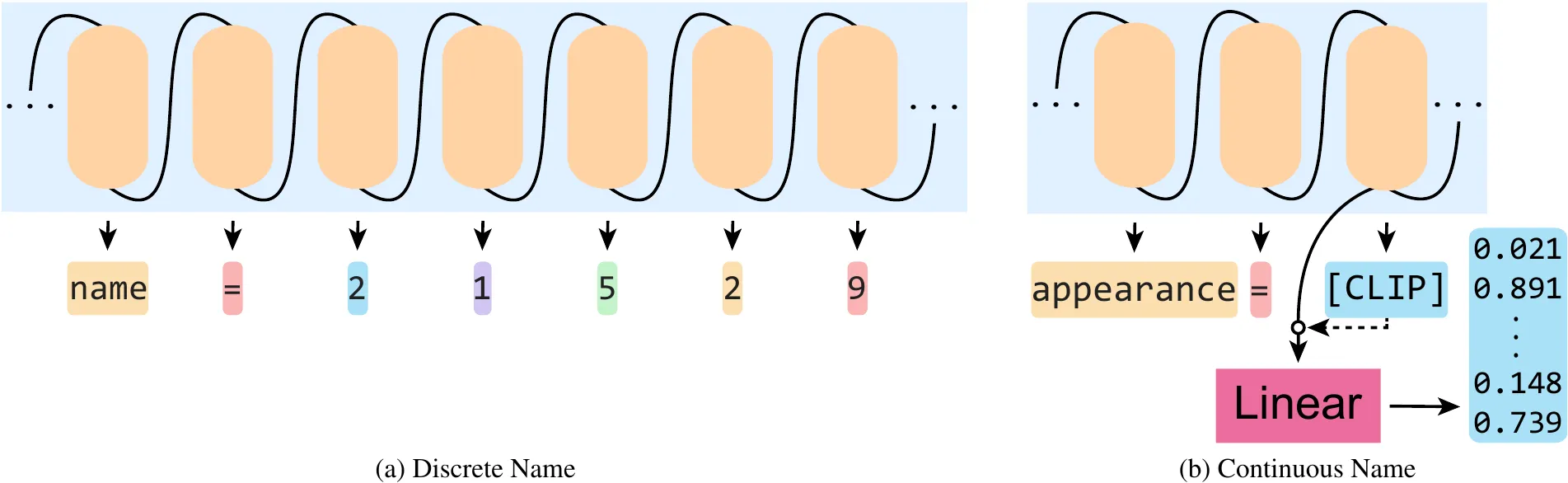
We observe that with the incorporation of the CLIP-projection head, the model demonstrates the ability to scale, estimating objects in scenes featuring much-expanded asset diversity. Our approach successfully reconstructs animals and their environments in real images:








































Paper
|
|
AbstractThe idea of 3D reconstruction as scene understanding is foundational in computer vision. Reconstructing 3D scenes from 2D visual observations requires strong priors to disambiguate structure. Much work has been focused on the anthropocentric, which, characterized by smooth surfaces, coherent normals, and regular edges, allows for the integration of strong geometric inductive biases. Here, we consider a more challenging problem where such assumptions do not hold: the reconstruction of natural scenes containing trees, bushes, boulders, and animals. While numerous works have attempted to tackle the problem of reconstructing animals in the wild, they have focused solely on the animal, neglecting environmental context. This limits their usefulness for analysis tasks, as animals exist inherently within the 3D world, and information is lost when environmental factors are disregarded. We propose a method to reconstruct natural scenes from single images. We base our approach on recent advances leveraging the strong world priors ingrained in Large Language Models and train an autoregressive model to decode a CLIP embedding into a structured compositional scene representation, encompassing both animals and the wild (RAW). To enable this, we propose a synthetic dataset comprising one million images and thousands of assets. Our approach, having been trained solely on synthetic data, generalizes to the task of reconstructing animals and their environments in real-world images. We will release our dataset and code to encourage future research. BibTeX@InProceedings{
|
